The motivation for this video comes from this CSS keylogger example shared on HackerNews,
twitter and reddit and it's incredible popular.
The github repository with this example has thousands of stars after just a day.
And I find this quite fascinating…
But before we get into this particular example, let's got back in time to 2012.
In 2012, almost 6 years ago of this video, I was still at the beginning of learning more
about security.
I was still reading and learning a lot of the very basics.
Like basic XSS vectors with <script>alert(1)</script>.
And a friend of mine invited me to a small closed hacker conference.
And so there I am, a complete noob feeling like I don't belong there watching these
talks.
And there was one talk called "Script-less attacks" - attacks in a post-XSS world by
mario.
So the premise of the talk, as you can infer from the title, is about a world without javascript
and without XSS issues.
It's a thought experiment first and foremost, because having such a situation where you
have an HTML injection with no javascript context is rare, maybe with more and more
content security policies a bit less rare, but in the grand scheme of the web, one could
argue that it's "irrelevant", or not really impressive because it might not have
much impact.
But to me this was blowing my mind.
This is research.
This is posing an interesting question and it makes you think about everything in a much
more intricate way.
You can learn the basics of XSS in an afternoon, but then pushing the boundaries and learning
how far you can take, that is where you get really good at it.
So…
What if we defeat XSS, what attack surface will remain and will it make a difference?
First of all you have to think about what even your goal is.
What would be the goal of XSS.
So in general we want to steal or access data we are not supposed to access and we wanna
do this with HTML that we can inject into the target website a victim visits.
So this talk shows a lot of different techniques and tricks using various features, to extract
different kind of information from the site.
That could be logging keystrokes or could also mean access form daya such as a CSRF
token, a password or a credit card number.
This talk is actually based on a paper with the same name and mario gave this talk several
times and I link a recording in the description.
But we had the rule for this talk, for this thought experiment, to not use any Javascript.
To not use any XSS.
So the question is now, how can we mitigate or bypass CSRF protection by just using CSS
and other inactive stuff?
Not using any javascript atl all.
Can we do this?
Well, some other people did this already some years ago, and I think there was also a bluehat
talk, and an excellent one too.
It was sirdarckcat, gareth heyes and david lindsey they already did it.
And there is still a demo out there you can have a look at.
And they also used CSS.
Cascading Stylesheet.
So what they did, they were abusing attribute selectors.
And they were saying: hey, select everything that has value, or every input element that
has a values, that is starting with a letter "a", and give it a background image, that
is indicating that we have the letter "a".
So if there was "a" as the first letter, a request was sent out.
Same with b, c, d, e, f, g.
And they could also do this with the last letter, or with some letter in between.
What they could not do, is select me the n-th character.
So they couldn't do give me an element where the second letter is actually the a,b,c or
d or whatever.
So they had to bruteforce a lot.
They had to write a lot of CSS to make this happen.
It was like loads, literally megabytes of stuff they had to inject.
So it was not very feasible.
Also didn't scale, and attackers like to scale.
And then mario shows a more efficient and more insane technique to pull this off.
But as he pointed out, this idea with attribute selectors loading background images was already
introduced previously by Eduardo (@sirdarckcat - sorry.
No clue how to say that), Gareth Heyes and David (@thornmaker).
And now let's fast forward to 2018, to a tweet I came accross in Februray by Mike Gualtieri,
who apparently rediscovered this again independently.
You can see here how he explains the CSS attribute selectors and then uses the same background-image
loading trick.
He put a lot of effort into this, wrote a detailed article calling it "Stealing Data
with CSS" and even wrote a Chrome and Firefox extension that is removing these CSS rules
as a form of protection.
I feel a little bit bad for him because I think he thought he stumbled over something
new, but it was just a rediscovery.
But yeah, this can happen and happens in security a lot.
Different teams find stuff independently and maybe years apart.
And it's such an obscure technique as well, that it's very likely you haven't heard
of it before if you don't spend a lot of time with browser client side security.
And I guess I was just lucky that I saw mario's talk in 2012.
Now a couple of days later this CSS keylogger example turns up.
I'm not sure if it's a coincidence or if it was inspired by this article, but this
person created an extension that simulates a CSS injection into a page to steal characters
entered into an input field.
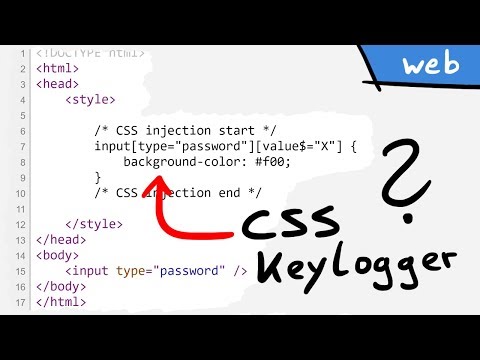
You can see the injected css here.
It uses CSS attribute selector for an input password field and depending on the value,
embeds a background image from a URL, which is sending that character to a server to collect
it.
Though there is one small detail here that is quite interesting.
You see the CSS attribute selector works on the value attribute.
So this doesn't work in a plain HTML example.
Even though the entered text is available via the value property on the input element,
it's not the attribute value.
So the CSS selector doesn't kick in.
That's also why the password stealing example of the blog post actually sets the value,
of the input element it wants to extract the characters from, via a GET parameter.
So this is a technique to steal attribute data.
So another good target for this technique is the CSRF token that is usually set as a
hidden input value.
But the github example worked on intputs where you just type in?
Well that's the small detail that is quite interesting.
Essentially what is happening is, that a lot of javascript frameworks, such as react react
on events like typing into a field and automatically propagate these values to internal variables,
but also properly set the value attribute of the input element.
So essentially it can be boiled down to this example.
On each keyup event, we set the value attribute to the value property.
As a test I have defined here a single rule that only kicks in when the character X is
detected.
So when we now test it, and type something in the field, we see the value attribute updating
accordingly, and with an X the CSS rule kicks in that could be used to extract the data.
And you can easily observe this behaviour on the instagram login form as well.
So IF instagram had an HTML injection, and for some reason couldn't execute javascript,
you could use that to steal input form data.
Pretty neat behaviour right?
Ok… so I don't want to talk down this research.
And I'm definitely not saying this research was stolen or anything.
I give them the benefit of the doubt, especially Mike seems to be very genuine and discovered
it by himself, which I think is impressive and is proof that he is very creative in his
thinking.
I mean, I didn't come up with this, and I'm not sure if I ever would have, I just
knew about it because I had heard it in a talk.
But I think it's an amazing example of, research that has been done in the past and
is rediscovered or resurfaces in a way.
The numbers of people interested in the CSS keylogger example shows that a ton of people
have never heard about it, didn't realize it was possible.
And so now more people learn about it.
And that's awesome.
So I hope I made it clear that there is research contribution I acknowledge and I don't want
to be one of those people who bolster themselves for having heard of it already in 2012.
However I want to put this also into perspective and I have to criticise a few things.
The name.
CSS Keylogger.
Okay, maybe the person who created it didn't anticipate how popular it will get, it's
a short descriptive name somewhat fitting, but daaamn, this is so easily misinterpreted
by most people and is fearmongering.
When we hear keylogger we usually think of a malicious malware running in the background
recording every keystroke, and that is terrifying.
Then sometimes we hear about browser keyloggers, and that is already a bit more nuanced because
it usually refers to keystrokes captures on ONE particular website via javascript, which
usually is also fearmongering by piggyback riding on the "keylogger malware" term,
because in such a context it's not a system wide keylogger and the javascript could do
other stuff that is worse than just logging keys.
And now this CSS example is even less impactful than that.
This specific example can only capture attribute values and usually only CSS injection, no
XSS, is quite rare.
Like mario already stated in 2012, it's more of a thought experiment and an interesting
research question, rather than something realistic.
There are some interesting edgecases, for example how about reddit that doesn't allow
javascript but CSS customization, and so you should know this technique exists when you
are looking for security issues, but it's pretty much irrelevant for most of the world.
The real world impact might be low, but like I already said it is a mindblowing idea.
It's maybe comparable to the discovery of a new distant planet in a habitable zone,
many people say "who the f' cares about this here on earth" we have real problems.
But it is awesome research, it is pushing the boundaries of technology, it is helping
us understand the world better, and so these CSS attacks help us understand web technology
and threats better and that in itself is already awesome!
But it's a problem when this travels so far and gets so popular, scaring so many people.
This and many more techniques have been known for like a decade and that is proof that this
is not a problem or an attack you have to worry about.
So just chill, look at the underlying technical data, ignore the FUD about de-anonymizing
TOR users or "keyloggers" and just appreciate how you can twist CSS to do insane stuff.
Div tag position relative
Trả lờiXóa